The technology world is now well aware that the GPU is no longer a one-trick pony, having evolved well beyond its singular role of accelerating raster-based 3D graphics. A look at Nvidia’s recent market valuation (NVDA), flirting with the trillion-dollar mark, is glaring evidence of how GPUs—particularly Nvidia’s GPUs—now command a far broader market space, encompassing compute acceleration and, most notably, machine learning (AI). That expanding role has translated directly into today’s breakdown of Nvidia revenue, much different than in past years. Of Nvidia’s most recently reported quarterly revenue (ended April 30, 2023) of $7.2 billion, it was the company’s data center business that contributed the largest share at $4.3 billion.
While the GPU’s historic foundation in 3D visualization no longer gets top billing—that’s clearly AI these days—its role in interactive 3D graphics and an expanding role in rendering remain a core market and a contributor to the company’s coffers. Gaming markets accounted for $2.2 billion last quarter, and professional visualization added in another $295 million. But what earnings reports don’t detail are margins, and while $295 million might seem like a mere sliver of Nvidia’s revenue pie today, the professional visualization market’s contribution to profits surely play a more outsized role in the company’s bottom line.
At Siggraph in August, despite the majority of audience eyes and ears focusing on AI and the data center, Nvidia again gave the professional visualization market a respectful nod, introducing the latest member of its workstation-caliber RTX GPU line, the RTX 5000 Ada Generation.
The RTX 5000 Ada Generation
Nvidia’s latest Ada-generation GPU has already spawned two products for fixed/deskside workstations—led by the top-end RTX 6000 Ada Generation—as well as a slew of GPU modules for mobile workstations, all announced in unison as the first round of Ada-derived professional RTX GPUs in Q2 of 2023. As is customary, at least on the fixed/deskside half of Nvidia’s professional solutions, the first product incarnation launched for a new generation taps the biggest and highest-performance chip, and in the case of the RTX 6000 Ada Generation, that meant leveraging the AD102, the 76.3 billion-transistor (TSMC 4N custom Nvidia process) Ada flagship chip.
The RTX 5000 Ada Generation sits one notch below the 6000 on Nvidia’s price spectrum, but at a street price that will likely sit around $2,900 or so, it still classifies as an ultra-high-end product. In the RTX line, the RTX 5000 Ada Generation will succeed the duo of the RTX A5000 and subsequently released resource-boosted A5500, both derived from Ada’s predecessor, Ampere. Not surprisingly, the RTX 5000 Ada Generation offers resources trimmed down from the 6000 for Ada’s three primary classes of compute engines integrated in the architecture’s shader multiprocessors (SMs): CUDA cores, Tensor cores (to primarily accelerate machine learning), and RT cores (accelerating ray-tracing algorithms for rendering). Whereas the AD102 and RTX 6000 Ada Generation tout 18,176 CUDA cores, the RTX 5000 Ada Generation offers 12,800, 400, and 100, respectively.
Spinning a resource and cost-reduced sibling product often means using a resource and cost-reduced sibling silicon. Nvidia already has several such leaner chips already powering the mobile Ada line, but the next biggest AD103 doesn’t quite offer enough to put the RTX 5000 Ada Generation’s performance level where Nvidia would want to position it: as a compelling step up from the previous A5000 and A5500. Instead, Nvidia appears to have opted for another common performance-reduction technique: using the flagship AD102 but disabling (either by intention or possibly functionality binning) a portion of the flagship’s resources.
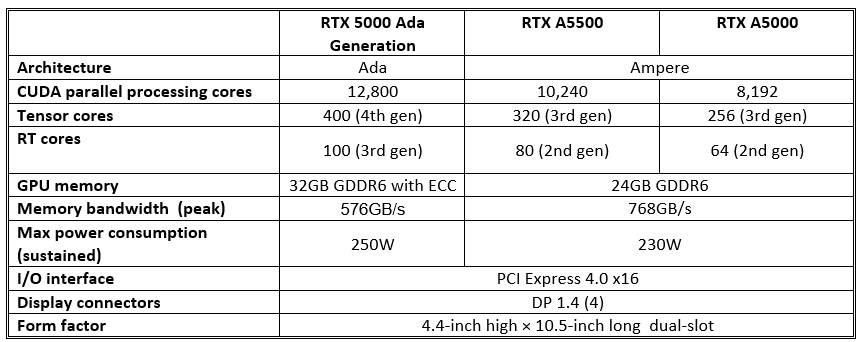
A scan of the RTX 5000 Ada Generation’s salient hardware metrics generally fit expectations: that is, all indicate more aggregate capabilities than the previous generation at roughly the same design power. One notable exception is peak memory bandwidth, which actually decreases. Reining in power is the likely motivation behind the design choice, but it’s also a testament to Ada’s architectural efficiency (and onboard cache) that it can achieve higher levels of performance with less total bandwidth at its disposal.
RTX 5000 Ada drives up visual computing performance for 3D graphics and 3D rendering
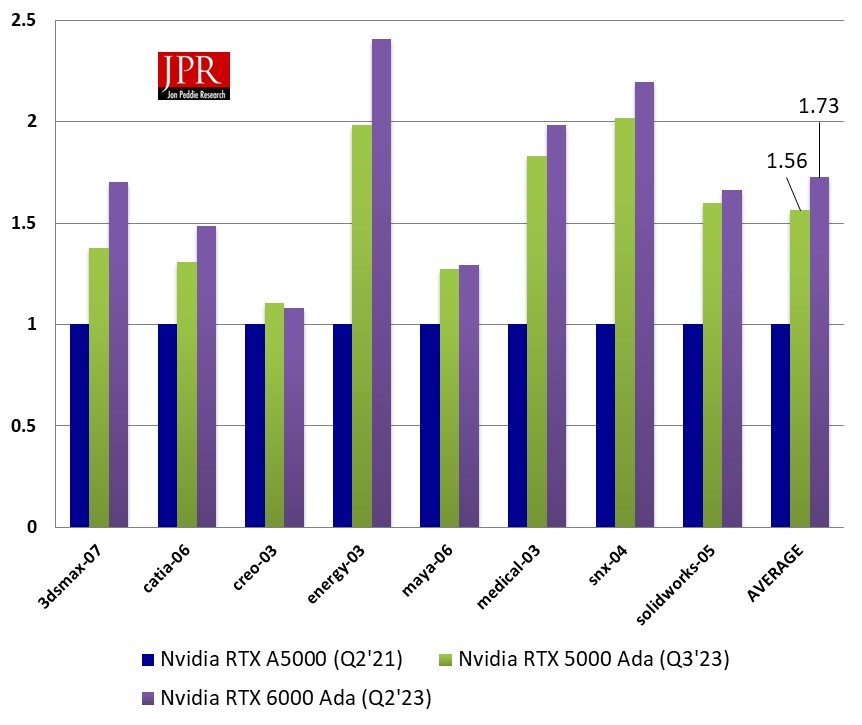
When it comes to more traditional, interactive 3D graphics, SPECviewperf (in the latest 2020 version) remains the go-to benchmark for CAD and other applications heavy in professional visual processing. Testing with SPECviewperf 2020 yielded the following results, run on the same high-performance system, swapping in both the RTX 5000 Ada Generation and previous Ampere-generation RTX A5000 (data for the A5500 was not available).
The RTX 5000 Ada Generation GPU ran through the SPECviewperf 2020 viewsets on average 56% faster than the RTX A5000 (with the A6000 Ada Generation about 73% higher). Subjectively, I tend to judge a 50% gain as an admirable and compelling gain for a generation-to-generation improvement in 3D graphics throughput, and the RTX 5000 Ada Generation checks that box with some headroom. (Bear in mind, the A5000 kicker, the A5500, was not tested here and likely would deliver results somewhere between the two.)
GPU rendering: 3D graphics is no longer the only, or even most critical, visual processing workload
While still being the foundation of most visual computing workflows, 3D graphics is no longer the only GPU function to assess. With the advent of on-chip ray-tracing hardware, along with the GPU’s ever-improving aptitude in GPU computation and machine learning, there’s more value to be exploited in a next-generation product.
Let’s start with the next most valued function, at least with respect to client-side visual processing: rendering. Besides simply offering more CUDA, RT, and Tensor cores than the comparable Ampere-generation chips, Nvidia amped up the performance and functionality of each core moving to Ada (with 4th-generation Tensor core and 3rd-generation RT core architectures). For example, the RT cores themselves have been upgraded to provide an Nvidia-claimed two to three times increase in ray-tracing throughput over Ampere. And while 3D graphics processing primarily leans only on the CUDA cores, it’s rendering that represents a crossroads of algorithms that leverage capabilities of all three cores.
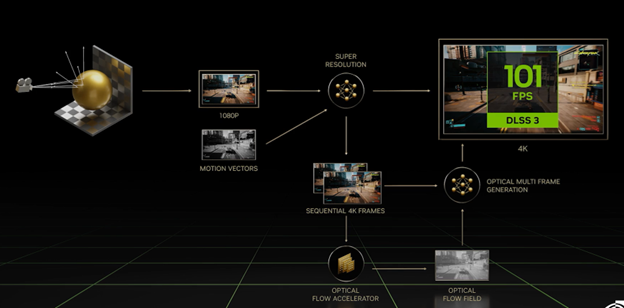
Consider DLSS 3, which extends on the AI/rendering synergies previously exploited in Ampere and Turing DLSS and DLSS 2 (Ampere’s predecessor). The preceding algorithms leveraged machine learning to intelligently fill in pixels or rays (which correlate in number to viewport pixels in rendering), thereby cutting the time required to arrive at the final rendered image. In Ada, DLSS 3 takes that to a logical next step, but in the temporal rather than spatial domain. Rather than filling in pixels or rays within the same frame, DLSS 3 allows for trained neural networks to create intermediate frames, thereby increasing frame rate with, again, much less brute-force visual processing.
But the technique works differently in the temporal domain. Think of DLSS 3 interframe generation as working from a semi-encoded digital video stream of rendered images. In virtually all modern digital video codecs, only some frames are fully, atomically encoded (a la DCT as in JPEG). Rather, encoded motion of pixel areas from previous (or future) frames are used to interpolate intermediate frames. With DLSS 3, those motion vectors are fed into a neural network using the generative output to re-create pixels of the intermediate frames, thereby reducing the total workload for rendering every individual frame.
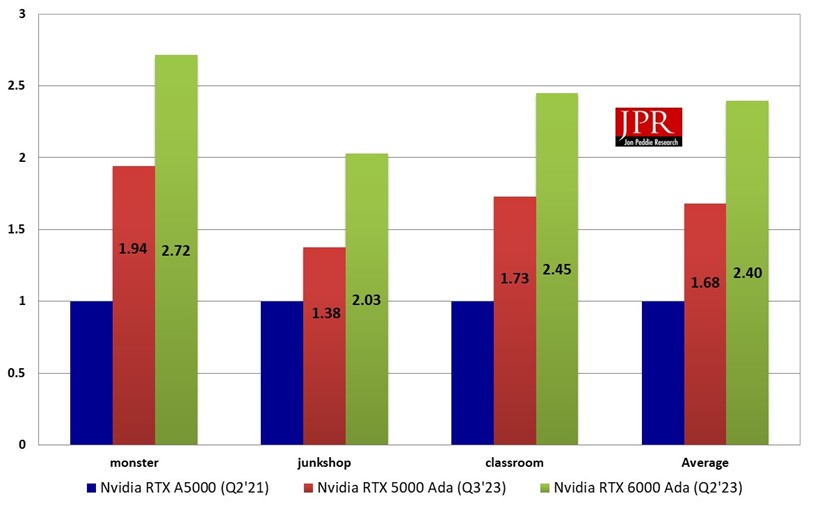
With all that additional processing resources across the board—CUDA, RT, and Tensor cores— we should expect a healthy increase in rendering throughput moving from the Ampere RTX A5000/A5500 to the RTX 5000 Ada Generation. Results from testing both the RTX 5000 Ada Generation and previous-gen RTX A5000 confirms as much, with the former outperforming the latter by 68% (average of normalized scene scores) on the Blender Cycles benchmark, a margin even higher than that of SPECviewperf 2020’s 3D graphics.
Ada is propagating step by step down Nvidia’s workstation-class RTX GPU line, now occupying the familiar 6000, 5000, and 4000 model-number positions in the portfolio. So far, Ada is providing compelling speedups from those models’ Ampere predecessors, both for traditional 3D raster graphics but—even more so—in rendering.
While a bit more affordable than the 6000 Ada Generation—at $6,800, serving a tiny corner of the market—the 5000 Ada carries a $2,900 (estimated street) price tag that will make it far from pervasive as well. But subsequent steps down the price curve are likely, with Ada presumably refreshing the far higher volume 2000 tier in the near future. Nvidia’s 2000-level professional GPUs typically sit in the $600–$700 (street price) range, which would put Ada in the sweet-spot, highest-volume, midrange of the market.
There’s every reason to expect an eventual midrange RTX Ada GPU would yield similar generation-to-generation speedups as the RTX 5000 Ada and 6000 Ada, making its advantages in performance and functionality accessible to the breadth of workstation-caliber computing markets. (It’s worth noting that today’s entry level of the market, served by Nvidia 1000/600/400-type numbering, is currently served not by the Ampere generation but Turing, Ampere’s predecessor. As such, getting Ada to trickle down to price points south of $500 or so may take significantly longer.)
An in-depth look at the workstation market can be found here: JPR Workstation Professional Computing Markets and Technologies report series.