Google DeepMind’s Gemma AI models are a collection of lightweight, open models built from the same technology that powers the Gemini models. The company previously began offering four Gemma 4 models suitable for multimodal input tasks, each with various parameter sizes—two on lower end, two on the higher end—tailored for specific needs. The Gemma 4 12B open-weight model has joined the family, falling somewhere between the quad. The 12B sports an Apache 2.0 license like its siblings and is optimized for running locally on a standard business laptop.
Google is one of the AI model providers that caters to a wide market swath. On the high end (for exceedingly complex tasks), there is Google Cloud AI, offering powerful machine learning tools and pretrained models for enterprise-level applications; late last year, it announced Ironwood, its 7th-gen TPU specifically designed for inference associated with computationally demanding models. On the opposite end, there is the Gemma line for lightweight tasks. Days ago, Google again turned its attention to this segment and line, filling out the Gemma 4 family with the Gemma 12B, a mid-level variant.
The new Gemma 12B, tuned for text generation, coding, and reasoning, is a 12 billion-parameter open-weight model. It is also optimized to run locally on a standard enterprise laptop, using just 16 GB of VRAM or unified memory, thus eliminating the need for excessive (and expensive) RAM. There’s a convenience factor with the new model as well: Enterprise users can use it to continue working with AI when Wi-Fi is unavailable or when security concerns call for offline work.
The Gemma 4 12B is the newest member of Google DeepMind’s Gemma 4 family of open models, released in April, that use an open Apache 2.0 license (free to download and operate). The Apache 2.0 license replaced the restrictive custom Gemma license found in the earlier Gemma 3 versions. The four prior models fall into two use categories—two (E2B and E4B) are geared for ultra-mobile, edge, and browser deployment, and the two others (the 31B dense model and highly efficient 26B A4B MoE model) are for more serious local inference, where quality and maximum capability, respectively, are the center of focus. The new Gemma 4 12B straddles the middle.

Table 1. Gemma 4 model comparison.
The Gemma AI models are a collection of lightweight, open models built from the same technology that powers the Gemini models and are designed to run locally. Gemma models are smaller and optimized for local and edge deployment, whereas Gemini models are larger and only available through Google’s API.
Like the rest of the Gemma 4 family, the Gemma 4 12B is multimodal, capable of handling text and image input and generating text output, bringing native audio and vision understanding directly to local environments. Whereas the other Gemma 4 models use dedicated encoders to process multimodal data before passing it to the LLM, the Gemma 4 12B is natively multimodal and eliminates those encoders, reducing latency.
Since the model is encoder-free, its deployment size is well-suited for consumer devices and streamlined local execution.
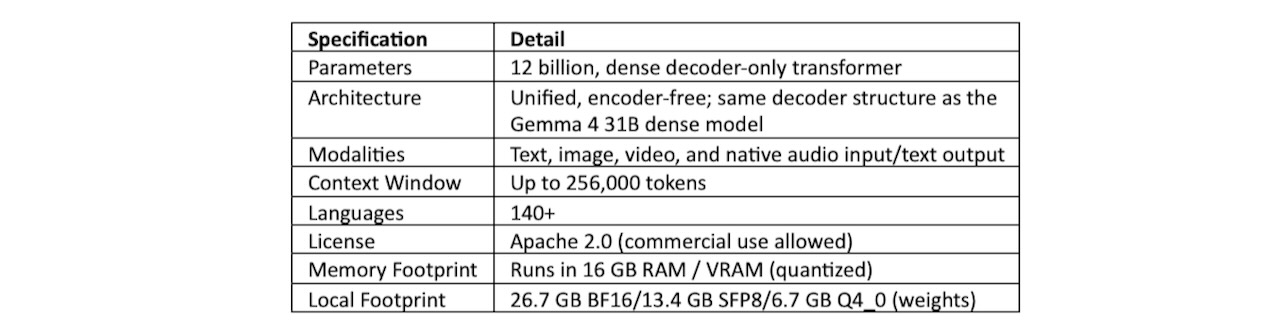
Table 2. Gemma 4 12B specs.
The Gemma 4 12B does not require an AI accelerator to run locally but can perform complex multi-step reasoning and agentic workflows nearing the larger Gemma 26B MoE model on standard benchmarks but at less than half the total memory footprint, according to Google.
Gemma 4 12B highlights include:

Gemma 4 12B is available for download on Hugging Face and Kaggle, and for use on Google AI Edge Gallery, a destination for running open-source LLMs on user devices.
LIKE WHAT YOU SAW HERE? SHARE THE EXPERIENCE, TELL YOUR FRIENDS.