In 2024, AI advancements in audio and video, driven by companies like Microsoft, Amazon, Google, and Tencent, are expected following extensive testing. The collaboration between Intel’s Granulate and Databricks aims to enhance data management efficiency. Notably, AMD’s AI efforts, including the MI300X CDNA 3-based chiplet AI processor, show commitment to leadership in the expanding AI market, predicted to reach $400 billion by 2027. AMD’s advancements, showcased at the company’s AI conference, include the MI300A APU, ROCm 6 software, and the El Capitan supercomputer for Lawrence Livermore National Laboratory.
What do we think? Audio (including translations) and video generated and enhanced by AI will take off in 2024 now that most of the testing (done by an unofficial multimillion-person beta test force) is just about finished. We will also see amazing examples of new discoveries of an individual’s data, revealing things not seen before, and those cases feeding into a database of collective results helping to predict incidences normally not considered. As more real, definitive, and defendable data is presented to the generative AI (GAI) models, the so-called hallucinations will disappear (sadly, we won’t notice the difference).
The big cloud companies are rolling out GAI for consumers now, with Microsoft’s Copilot, Amazon, Google, and Tencent right behind them, and in 2024, almost anyone who uses a computer or smartphone will be engaging with GAI, although they may not be aware of it (and they shouldn’t have to be if it’s doing its job right).
Nvidia gets a lot of credit for Cuda as an enabler for GAI, and that is somewhat correct if you are only considering Nvidia GPUs and SoCs. Lots of competition is coming after Nvidia’s dominant position in GAI processing and acceleration. Amazon, Google, Tenstorrent, and a half dozen others including AMD and Intel are prime examples. And here is where the other companies must pick their fighting ground. Only AMD and Intel have the breadth, technology, and products to meet Nvidia head-on. Intel has super powerful CPUs and a GPU potentially capable of being GAI accelerators (e.g., Falcon Shores). AMD has changed the landscape with its just announced MI300X.
AMD, and others like Qualcomm, see the mass market of AI inference in client devices like PCs in hybrid mode with the cloud as well; so far, Intel and Nvidia haven’t announced that category, but AI PCs are being spoken about, and Nvidia is very active with its AI-based DLSS.
Building GAI models is extremely complicated and expensive, and so only the big companies will be able to make the investments in hardware, software, and people to get systems running that can be used in an inference model on client devices. That doesn’t bode well for the start-ups because big companies like to deal with big companies (someone with deep pockets they can sue if things go wrong). So the start-up semi companies need a big partner like Amazon, Google, Meta, and Tencent.
AMD’s announcement this week is a clear unambiguous statement of the company’s intentions, capabilities, and products to be a leader in the total AI market which could reach $400 billion by 2027.
AMD takes a bold step forward in GAI, challenging Nvidia
For a variety reasons, AMD has followed Nvidia on GPUs since the early 2000s. As of late, you could say AMD was a fast follower. AMD didn’t imitate Nvidia (on most things), but came up with a variation and improvement, the benefit of having a model to copy and enhance.
AMD adopted open systems in the early 2000s, for philosophical and economic reasons, and they’ve stuck to that thinking, though with one or two notable exceptions like their infinity fabric (more on that later) and maybe ROCm.
AMD has plenty of smart people (25,000 compared to Nvidia’s 26,200), but they are split between CPU and GPU, whereas most of Nvidia’s people are GPU oriented. So even though AMD is probably working on the same things as Nvidia, with half the workforce, they are almost always a little behind on announcements. But when they do come out, very often they amaze us. They amazed us this week with their AI rollout.
At AMD’s AI conference in a fancy upgraded hotel in San Jose, California, CEO Dr. Lisa Su gave an overview of the AI market and said whereas most people thought it growing at 50% and hit $45 billion in 2023, she thought it was growing even faster, maybe at 70%, and would hit $400 billion by 2027—faster than anything she’s ever seen before.
Compared to AMD’s previous generation, said Su, CDNA 3 delivers up to 1.5× more memory, 1.6× memory bandwidth, 256MB Infinity Cache, and support for TF32, FP8, and sparsity.
The availability and supply of GPU compute is the single most important item in the adoption of AI.

The MI300X is constructed using a dozen 5nm and 6nm chiplets, starting with four I/O dies with 256MB of Infinity Cache, in the base-layer 128-channel ACM interfaces, PCIe Gen 5, fourth-gen Infinity Fabric providing 890GB/s. They stack eight CDNA 3 accelerators, which Su says delivers 1.6 PFLOPS of FP16 and 2.6 PFLOPS of FP8 performance. Then, they connect the 304 compute units with TSVs (through-silicon vias), which gives them 17TB/s bandwidth. To that, they connect eight stacks of HMB3 for a total of 192GB of memory at 5.3TB/s bandwidth.

Su said it’s the most advanced product they have ever built and claims it is the most advanced AI accelerator in the industry.
This was a capabilities and commitment announcement, and not a product rollout, so the specifications were a little light. Probably AMD will do a full-blown product announcement at or near CES—you know, CES, the supercomputer and AI stack conference… huh?
To meet that demand with leading technology, Su announced the company’s new CDNA 3 architecture in the new chiplet-based, 152 billion transistor MI300X AI GPU. It is supercharged compared to the previous MI250 introduced two years ago and delivers over 3× the performance.
As you might expect, the MI300X is better at everything, and in some cases, astonishingly better. But this time, mild-mannered and polite AMD didn’t just compare their new GPU to their previous GPU; they made a head-on comparison to Nvidia’s H100.
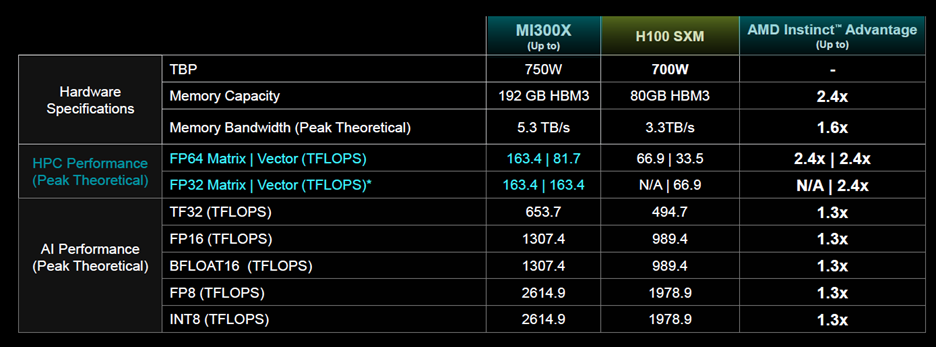
No one discussed GPU or tensor cores or caches, but they did discuss TFLOPS, TOPS, FPP, and Instinct’s 192GB/s of HBM3 with 5.3 TB/s memory bandwidth. Su said AMD Instinct MI300X accelerators are powered by the new AMD CDNA 3 architecture. When compared to previous-generation AMD Instinct MI250X accelerators, MI300X delivers nearly 40% more compute units, 1.5× more memory capacity, 1.7× more peak theoretical memory bandwidth, as well as support for new math formats such as FP8 and sparsity; all geared towards AI and HPC workloads.
AMD compared raw performance, too.
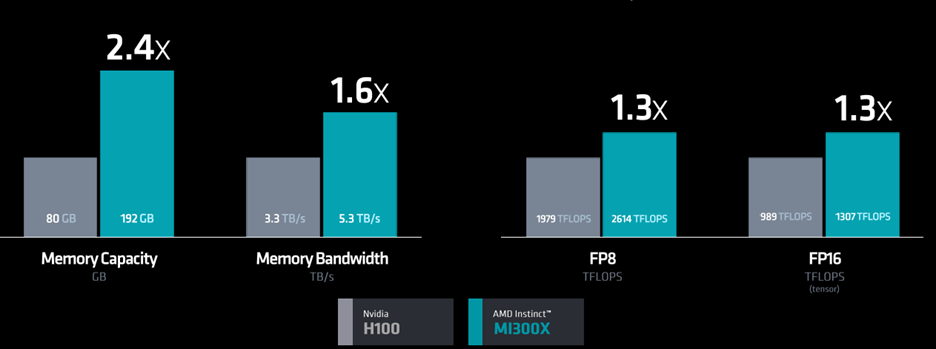
Yes, of course they handpicked the parameters and features they were best at, but AMD also made several comparisons to performance in various applications.
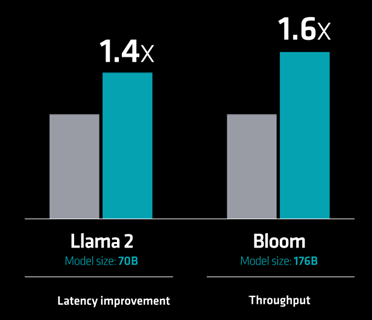
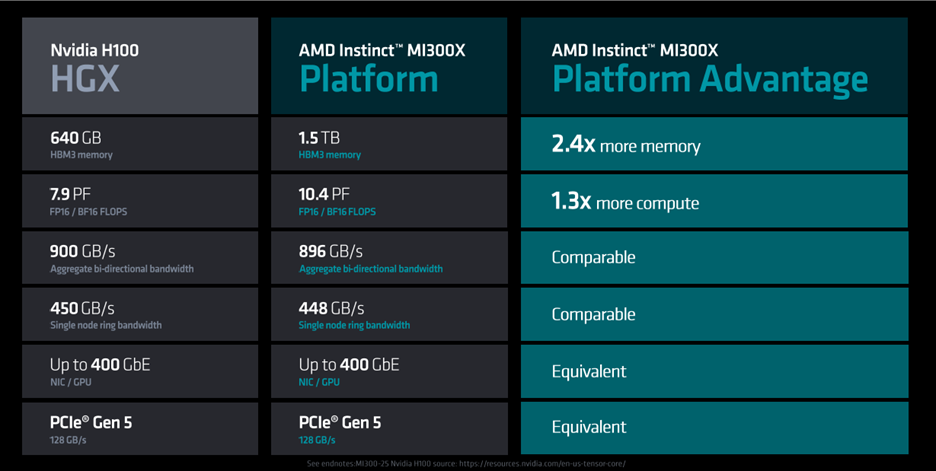
And AMD didn’t stop with just a GPU, they met Nvidia on the system front, too, and announced their Instinct platform, which is strikingly similar to Nvidia’s DGX. But, that could be because there aren’t a lot of options (possible or wanted) in server chassis—it’s built on a standard OCP sever design. Su said their eight-GPU system outperforms Nvidia’s by 1.4× to 1.6× on LLM.

The system is designed to be air-cooled (hence the giant heat sinks), and although not specifically stated, it was assumed the CPU would be the new Ryzen 8400.
Specificationwise, it compares very favorable to Nvidia’s offering.
AMD rolled out heavyweight partners from Dell, Databricks, Essential AI, HP, Lamin, Lenovo, Microsoft, Meta, Oracle, and Supermicro. Supermicro’s CEO, the irrepressible Charles Liang, was the only one who put Dr. Su on the spot and said they could ship more if they could get chips—a telling comment.
And speaking of personalities, the credible and charming President of AMD, Victor Peng, announced ROCm 6.0 was now available, which is as close as AMD gets to Intel’s OneAPI, but they didn’t spend a lot of time on that. However, Peng did say ROCm 6 software represents a significant leap forward for AMD software tools, increasing AI acceleration performance by 8× when running on MI300 series accelerators in Llama 2 text generation, compared to previous-generation hardware and software. Additionally, ROCm 6 adds support for several new key features for generative AI including FlashAttention, HIPGraph and vLLM, among others.

Forrest Norrod, AMD’s executive vice president and general manager of the Data Center Solutions Business Group, had a couple of announcements, too.
The big news was a chiplet-based Instinct-inspired APU to be called the APU datacenter MI300A. Like big brother Instinct, the chiplets are laid on top of IO, it has HBM3, and can deliver 61 TFLOPS (on a node basis). It is designed to compete with Nvidia’s Hopper Arm-based SoC, and AMD claims the MI300A will deliver 1.8× the performance of Hopper—a definite in your face, Nvidia.
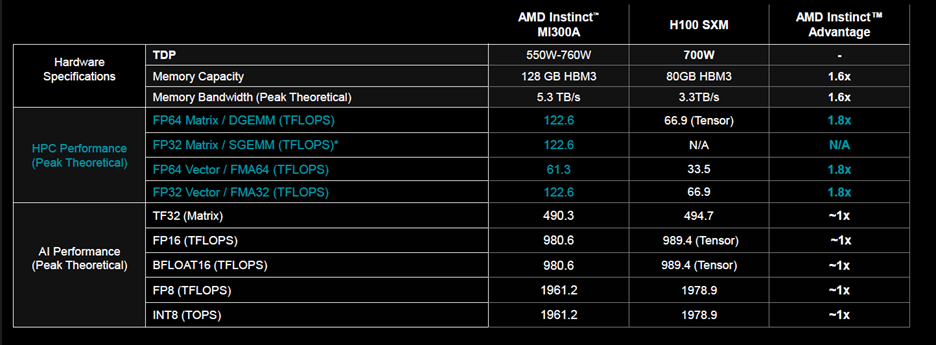
Norrod went on to say the AMD Instinct MI300A APUs benefit from integrating CPU and GPU cores on a single package, delivering a highly efficient platform, while also providing the compute performance to accelerate training the latest AI models. And he cited the company’s 30×25 goal, aiming to deliver a 30× energy efficiency improvement in server processors and accelerators for AI training and HPC from 2020–2025.
HP helped AMD announce El Capitan, the next super-duper computer destined for Lawrence Livermore National Laboratory (LLNL). HP’s Trish Damkroger, SVP and CPO for HPC, AI, and labs, was on hand to help Norrod celebrate breaking the exascale barrier.

Dr. Su returned to the stage and spoke about NPUs and how there were two backplane and other communications schemes, InfiniBand and Ethernet. With Ethernet reaching 400 Gbps currently (the current state of the art allows a maximum speed of 40 Gbps), it was the best choice, and of course, AMD has a solution. But, being AMD, they wanted it to be an open source (Mellanox originally had been proposed), but AMD and its friends have set up the Ultra Ethernet Consortium (UEC) for an Ethernet-based communication stack architecture for high-performance networking. Intel is a member, but so far Nvidia is not.
In conclusion, Sue said she hoped we could see that AI is absolutely the number one priority at AMD.
