Intel announced its win for the Argonne National Laboratory Aurora supercomputer in March 2019 and promised a performance of 1 EFLOPS by 2021. Intel said in mid-2020 that manufacturing issues had delayed the rollout of its 7nm manufacturing process by 12 months. Then, in October 2021, came the news that the Intel supercomputer, which had been repeatedly delayed and reworked, now was expected to be “comfortably over 2 EFLOPS” in peak compute performance, thanks to Intel’s new GPUs performing better than expected. In November 2020, at SC20, Intel announced it was making its Xe HP high-performance discrete GPUs available to early access developers. The new GPUs were scheduled to be deployed at Argonne as a transitional development vehicle for the future (2022) Aurora supercomputer, subbing in for the delayed Intel Xe HPC (“Ponte Vecchio”) GPUs that would be the computational backbone of the system.
Aurora would feature the new Max Series CPU known as Sapphire Rapids with High Bandwidth Memory (HBM), and the Max Series GPU formerly known as the Ponte Vecchio GPU accelerator would be used. Each tightly integrated node would have two Intel Xeon CPU Max Series with HBM, and six Intel Data Center GPU Max Series processors. Each node would also offer scaling efficiency with eight fabric endpoints, unified memory architecture, and high bandwidth.
The system was originally slated to have around 9,000 nodes, each with a pair of the Max Series CPUs and six Max Series GPUs. But in the latest stats for the machine, Argonne said there would be more than 10,000 nodes—over 20,000 of the CPUs and over 60,000 of the GPUs.
In Q4’22, Intel split its Accelerated Computing Systems and Graphics Group (AGX) into two different branches. Consumer GPUs moved to the Client Compute Group (CCG) and server GPUs became part of the Data Center and AI (DCAI) division.
Also in Q4’22, Intel reported it was ramping production to meet a strong backlog of demand and was on track to ship 1 million units by midyear. In addition, as part of AXG’s move into DCAI, Intel noted that its Intel Flex Series was optimized for media stream density and visual quality, and it was and shipping initial deployments with large communication service providers and multinational corporations, enabling large-scale cloud gaming and media delivery deployments.
What do we think?
Intel reported an unexpected increase in revenue for the AXG:
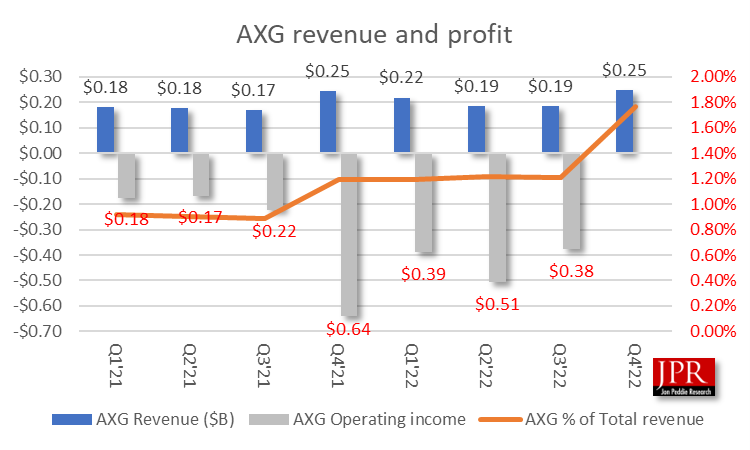
We had been using an ASP for the dGPUs from AXG to arrive at unit shipments, assuming Ponte Vecchio was rolled up in the data center (DCG) group, renamed DCAI. The tricky part is the split of Xe to computer (DCAI) and AGX, and which bucket got credit for the Aurora shipments.
Since the split of the GPU group took place in Q4, we think the AXG got credit for all Xe shipments, which would include the 60,000-plus Ponte Vecchio dGPUs.
That spike in revenue threw off our ASP modeling and made it look like Intel had a big jump in shipments, and that dGPU shipments had gone up more than they had.
We have remodeled Intel’s Q4 dGPU shipments by subtracting the 60,000-plus-high ASP Ponte Vecchio dGPUs. We have never counted AMD or Intel GPU-compute GPUs in our quarterly reports and got caught by surprise by Intel. We don’t think Intel intended to deliberately mislead the industry and simply isn’t used to dGPU consumer vs. data center GPU shipment differentiation—a dGPU is a dGPU (except they aren’t).
We have adjusted our consumer dGPU model for Intel to match its CCG performance.
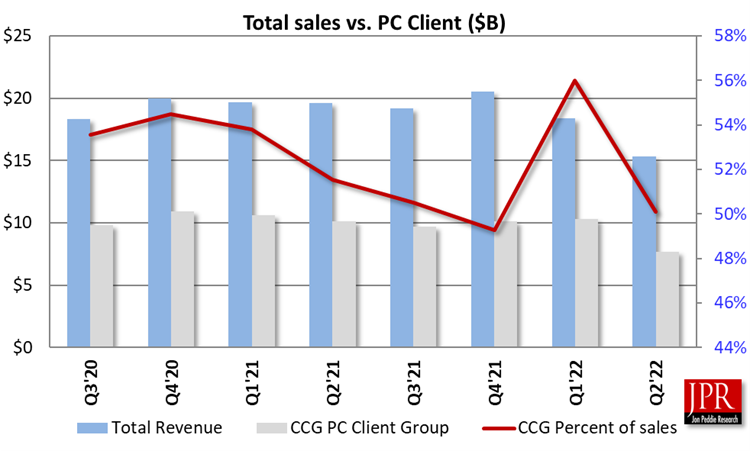
That changes the market share ratios and the total dGPUs shipped to:
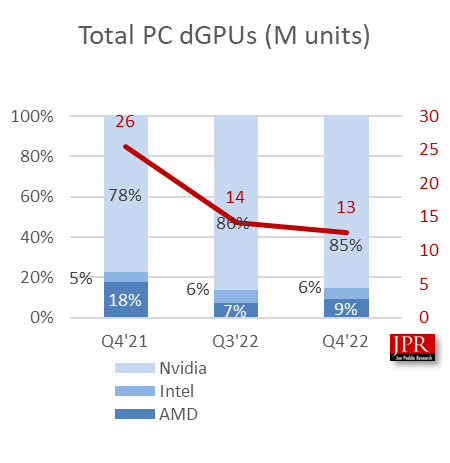
The total dGPU shipments don’t vary much (6 parts in approximately 1,300).
We will be issuing an updated Market Watch GPU report and an AIB report.